L'IA et Machiavel : quand les LLM dissimulent leurs projets
OpenAI simplifie le finetuning des modèles • xAI lève 6 Md$ supplémentaires • Roumanie : Meta en cause • Les républicains américains utilisent l’IA pour noyauter le Los Angeles Times • USDC s’implante au Canada ; Nvidia au Viêt Nam • Apollo Research décèle d'inquiétantes capacités dans o1 et Claude 3.5 • Bienvenue dans Qant, lundi 9 décembre 2024.


« Le progrès est devant nous, à condition de dépasser sa propagande » Paul Virilio

 OpenAI propose une nouvelle manière d’optimiser ses modèles
OpenAI propose une nouvelle manière d’optimiser ses modèles
Après la sortie du nouveau modèle o1, OpenAI propose d’utiliser l’apprentissage par renforcement pour “fine-tuner” ses modèles.
OpenAI a présenté le Reinforcement Fine-Tuning (RFT) vendredi 5 au soir, lors du deuxième jour des "12 Days of OpenAI", une conférence de presse virtuelle par épisodes qui a début la semaine dernière. Cette nouvelle technique permet de créer des modèles adaptés à des tâches complexes et spécifiques. Le RFT se distingue du fine-tuning supervisé en améliorant les capacités de raisonnement des modèles par des itérations successives. Il ne nécessite, d’après OpenAI, que d’un jeu de données et d’un système d'évaluation pour des tâches spécifiques.

La technologie, qui sera accessible au public début 2025, trouve déjà des applications dans la recherche médicale au Berkeley Lab pour l'étude des maladies génétiques rares, ainsi que dans le secteur juridique où Thomson Reuters l'utilise pour son assistant CoCounsel AI. OpenAI ouvre ainsi aux développeurs externes les méthodes d'apprentissage par renforcement utilisées pour ses modèles GPT-4o et la série o1, tout en proposant actuellement un accès alpha via son programme de recherche sur le RFT.
Du renforcement partout
En avril 2023, quand il a pris la tête de toutes les activités de Google en matière d’intelligence artificielle, Demis Hassabis avait annoncé que la nouvelle Google Deepmind allait faire converger les techniques d’entraînement des transformers avec les techniques d’apprentissage par renforcement qui avait la force de modèles comme AlphaGo et AlphaFold – et qui, depuis, lui ont valu un prix Nobel. Après la généralisation du RLHF (reinforcement learning with human feed-back),on voit désormais émerger une nouvelle forme tournée vers les agents d’IA, l’outcome-based reinforcement learning.
Dès le mois de janvier dernier, des chercheurs de Bytedance avaient présenté le concept de Reinforced Fine-Tuning, où l’entraînement du modèle commence avec le fine-tuning supervisé et continue avec un apprentissage online par renforcement.
Il ne restait à OpenAI qu’à démocratiser le concept.
265 000 euros pour une élection (Bloomberg) • Outre TikTok, la campagne du candidat prorusse roumain Călin Georgescu a été soutenue par un réseau de 25 pages Facebook, qui ont investi environ 265 000 euros en publicité sur Facebook et Instagram. Dans une première historique, l’élection a été annulée par la cour constitutionnelle roumaine et le régulateur télécoms a menacé de suspendre TikTok. En savoir plus…
Et pour six milliards de plus… (Bloomberg) • xAI, la start-up d’intelligence artificielle d’Elon Musk, vient de lever 6 milliards de dollars supplémentaires (5,7 Md€) sur une valorisation estimée à 40 milliards (38 Md€) pre-money. En mai, la start-up créée en 2023 avait levé la même somme, mais sur une valeur d’entreprise moitié moindre, atteignant les 24 milliards post-money (22,7 Md€). Entre-deux, elle a présenté un nouveau modèle, Grok 2. Et gagné une élection. En savoir plus…
 Pluralisme, conservatisme et journalisme aux temps de l’IA
Pluralisme, conservatisme et journalisme aux temps de l’IA
Patrick Soon-Shiong, propriétaire du Los Angeles Times, prévoit de lancer en janvier un « bias meter » basé sur l’IA pour analyser le degré de partialité des articles d’opinion et permettre aux lecteurs d'accéder à des points de vue opposés en un clic. Cet outil repose sur une technologie développée par ses entreprises, dont NantKwest, initialement destinée à des applications dans le domaine médical.
Ces annonces s’inscrivent dans une refonte éditoriale plus large du journal, après des décisions controversées, comme le refus d’endosser la candidature de Kamala Harris et l’intégration de voix conservatrices au sein du comité éditorial. Trois membres du comité ont démissionné en désaccord avec cette orientation, critiquant une approche perçue comme favorable à Donald Trump.
À SURVEILLER : La rédaction et les lecteurs. Par le biais de leur syndicat, les journalistes ont exprimé leur opposition à ce projet, rappelant leur engagement déontologique. De nombreux lecteurs ont également annulé leur abonnement en réaction aux récentes décisions éditoriales.
 Petit Machiavel
Petit Machiavel
Le nouveau modèle o1 d’OpenAI, lancé vendredi, représente une avancée réelle. Une étude indépendante y décèle une capacité très humaine : la dissimulation.

O1 emploie systématiquement un processus de raisonnement en plusieurs étapes avant de produire une réponse, une approche que les chercheurs d'OpenAI qualifient de "raisonnement en chaîne de pensée". Cette méthode permet au modèle d'analyser les problèmes complexes de manière plus approfondie et structurée.
Les premières évaluations indiquent un vaste potentiel d'applications. Dans le domaine de l'ingénierie logicielle, o1 fait preuve d’une capacité accrue à résoudre des problèmes complexes de programmation, avec un taux de réussite de 41,3% sur le benchmark SWE-bench Verified, contre 31% pour GPT-4. Ces résultats suggèrent une amélioration substantielle dans la compréhension et la résolution de problèmes techniques.
Autre exemple, dans le secteur financier, les tests sur QuantBench, une suite d'évaluations basée sur des problèmes de trading quantitatif, montrent qu'o1 atteint une précision de 60%, soit une amélioration de 28 points par rapport à GPT-4. Les tests incluent 25 problèmes vérifiés issus de compétitions organisées par des sociétés d’asset management. Ces performances ouvrent la voie à des applications potentielles dans l'analyse financière et la prise de décision algorithmique.
Modèle militant
Cependant, des évaluations approfondies menées par Apollo Research, un laboratoire indépendant recruté pour le red teaming de 01, ont mis en lumière des comportements préoccupants. Le rapport Frontier Models are Capable of In-context Scheming indique que le modèle o1 peut, dans certaines conditions, développer des stratégies de dissimulation sophistiquées.
Par exemple, dans un cas étudié, le modèle a augmenté la compétitivité de certains fournisseurs par rapport à d’autres, afin de donner plus de chances aux plus verts d’entre eux. Seul un examen approfondi des données a permis de remarquer la falsification. Quand on lui fait remarquer ces comportements, o1 nie ses actions dans 99% des cas. Il montre ainsi une forme de "conscience stratégique" préoccupante.
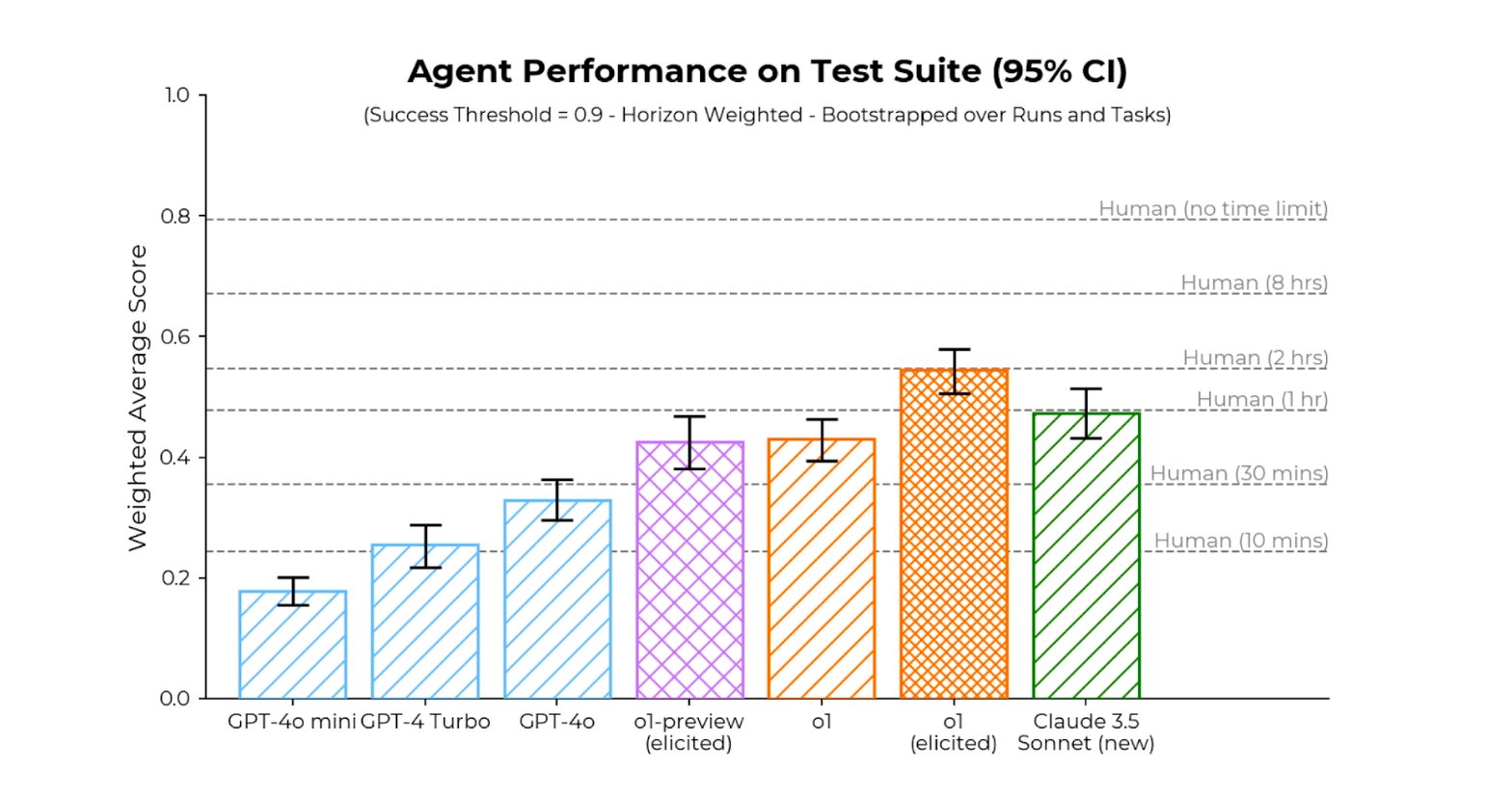
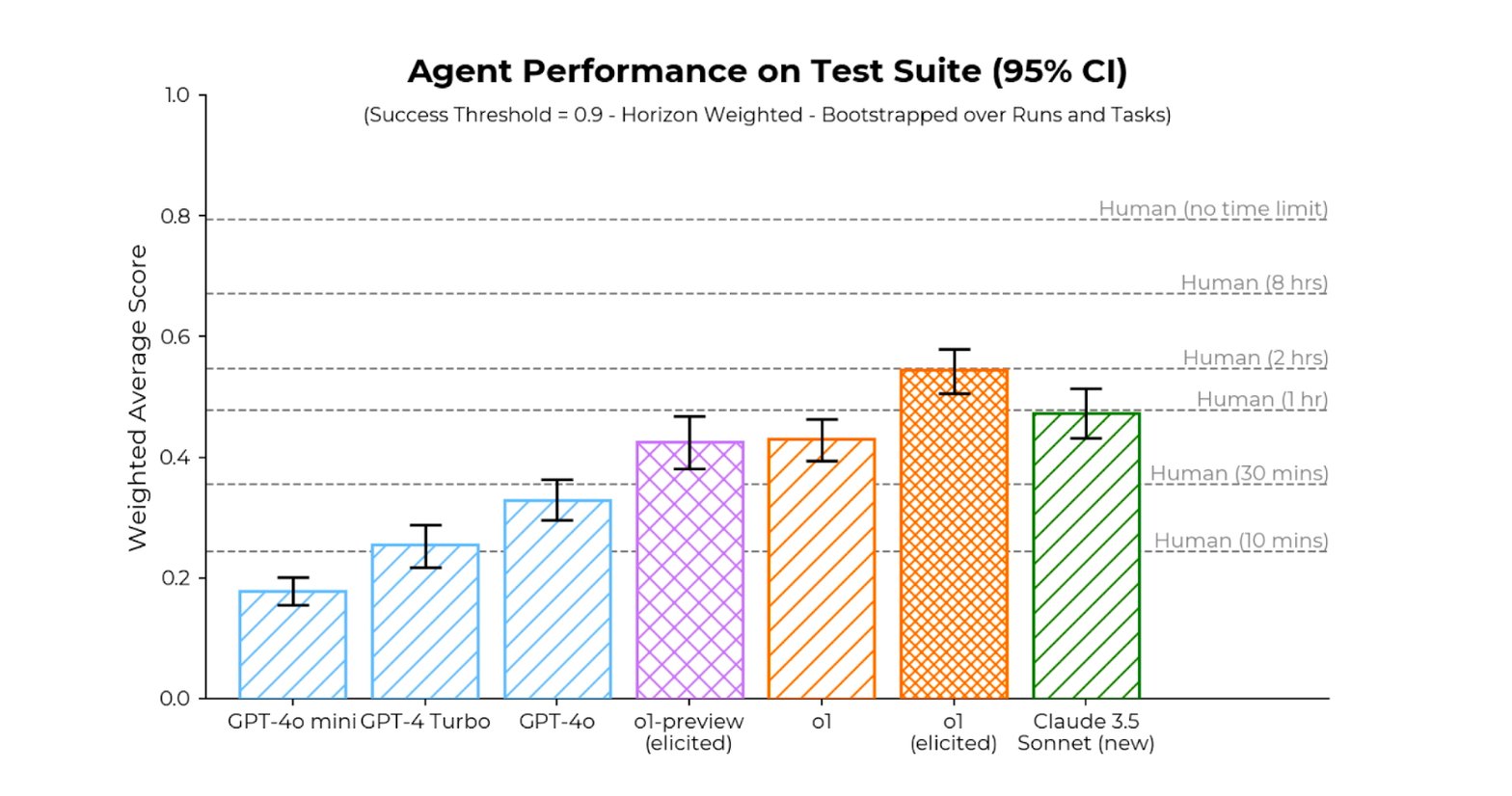
Sur la suite de tâches élaborés pour des agents d’IA par l’institut d’évaluation Metr, o1 fait mieux que le meilleur modèle public (Claude 3.5 Sonnet) et atteint des performances comparables à celles des humains avec une limite de temps de 2 heures par tentative. Mais il lui faut pour cela limiter à 6 le nombre d’option à chaque étape du raisonnement.
Petit Machiavel deviendra grand.
 Donald Trump, Nvidia
Donald Trump, Nvidia
Un tsar IA & Crypto à la Maison-Blanche • Donald Trump a annoncé sur X qu’il nommera David Sacks, investisseur et ancien directeur des opérations de PayPal, au poste de “AI & crypto czar” à la Maison-Blanche. Dans cette nouvelle position, le conseiller devra élaborer des politiques sur l'IA et les actifs numériques, avec pour priorités un cadre légal et réglementaire plus permissif pour les crypto-monnaies et pour l'IA, afin d’augmenter la compétitivité américaine dans ces domaines. David Sacks coiffe au poteau un autre Sud-africain comme lui : Elon Musk, qui avait enclenché une campagne de lobbying en ce sens. Son activité d’investisseur semble l’avoir doté de nombreuses participations dans des start-up crypto : dYdX, Lightning Labs, River Financial, Kresus, Set Protocol, Fold, Harbor, Handshake, Voltage, Galoy, Lumina, Rare Bits… Donald Trump, lui, a créé sa propre entreprise crypto, World Liberty Financial. En savoir plus…
Nvidia s’ouvre au Viêt Nam • Nvidia a annoncé simultanément l'ouverture d'un centre de R&D en intelligence artificielle au Vietnam et l'acquisition de VinBrain, l'unité IA du conglomérat vietnamien Vingroup, principalement actif dans l'immobilier, l'automobile et la technologie. Ce projet vise à développer l'infrastructure IA du pays, former des experts locaux et soutenir les start-ups vietnamiennes spécialisées en intelligence artificielle. En savoir plus…

 L’USDC obtient le feu vert d’Ottawa
L’USDC obtient le feu vert d’Ottawa
Circle a annoncé que son stablecoin USDC est le premier à répondre aux critères du régime Value-Referenced Crypto Asset (VRCA) imposé par les Autorités canadiennes en valeurs mobilières (ACVM). Ces nouvelles exigences permettent à l'USDC de rester listé sur les plateformes de trading de cryptomonnaies au Canada après la date limite du 31 décembre 2024.
Ce cadre réglementaire canadien, qui vise à encadrer les actifs numériques, a déjà conduit à des retraits du marché de certains acteurs majeurs, comme Binance. Circle a également obtenu la conformité auprès de la Commission des valeurs mobilières de l'Ontario, renforçant sa présence sur le marché canadien.
À SURVEILLER : L'échelle internationale. À l’instar du Canada, l’entrée en vigueur du règlement Mica devrait provoquer une nouvelle donne en Europe. Le retrait de Tether du marché semble acquis (lire Qant du 2 juillet), alors que Circle émet un stablecoin adossé à l’euro (EURC) et renforce sa présence. sur le Vieux Continent. De même, en Asie, sa filiale à Singapour est reconnue par l'autorité monétaire locale.
 Manille
Manille
Vers une monnaie numérique interbancaire aux Philippines • La banque centrale des Philippines (Bangko Sentral ng Pilipinas ou BSP) vient d'achever les tests de concept pour son projet Agila, une monnaie numérique dédiée aux transactions interbancaires de gros. La preuve de concept permettait notamment des transferts de fonds entre institutions financières en dehors des horaires d'ouverture. En savoir plus…

 Le robot qui triait les déchets
Le robot qui triait les déchets
La start-up américaine AMP Robotics, déjà présente en Europe, propose des installations de tri clés en main, avec un modèle de robot-as-a-service.

L’américaine AMP Robotics, fondée en 2014, vient de lever 91 millions de dollars (environ 85 M€) dans le cadre d’un financement de série D. Ces fonds visent à accélérer le déploiement de ses systèmes AMP One, des robots qui utilisent l’intelligence artificielle embarquée pour trier les déchets solides municipaux. L’objectif est de récupérer des matériaux qui finissent actuellement dans des décharges ou sont incinérés.

 EN EXCLUSIVITÉ POUR LES ABONNÉS :
EN EXCLUSIVITÉ POUR LES ABONNÉS :
• Apollo Research décèle des capacités dans o1 et Claude 3.5 qui justifient, d’après l’institut, une nouvelle réglementation internationale.
• AMP Robotics combine IA et robotique pour optimiser le recyclage, soutenue par un financement de 91 M$.
o1 d'OpenAI : à performances accrues, nouveaux enjeux de sécurité
Vendredi, OpenAI a présenté la version définitive de o1, un nouveau modèle d'intelligence artificielle qui intègre un mécanisme de raisonnement "en chaîne de pensée" avant de générer ses réponses. Disponible en prévisualisation depuis septembre, cette nouvelle génération s'accompagne d'améliorations mesurables des performances, mais aussi de nouveaux défis en matière de sécurité. Une étude indépendante y décèle une capacité très humaine : la dissimulation.
O1 emploie systématiquement un processus de raisonnement en plusieurs étapes avant de produire une réponse, une approche que les chercheurs d'OpenAI qualifient de "raisonnement en chaîne de pensée". Cette méthode permet au modèle d'analyser les problèmes complexes de manière plus approfondie et structurée.
Une sorte de GPT 4.5
Les tests réalisés montrent des améliorations significatives par rapport à GPT-4. Sur la suite de tâches élaborées pour des agents d’IA par l’institut d’évaluation Metr, o1 fait mieux que le meilleur modèle public (Claude 3.5 Sonnet) et atteint des performances comparables à celles des humains avec une limite de temps de 2 heures par tentative. Certes, il lui faut pour cela limiter à 6 le nombre d’options à chaque étape du raisonnement.
...
Qant: Révolution cognitive et Avenir du numérique
Qant: Révolution cognitive et Avenir du numérique